資料預處理在資料科學與機器學習中是一個很重要的步驟,預處理會對資料進行清理跟調整,避免模型因為資料不完整或產生的瑕疵而給出錯誤的結果。總而言之資料預處理可以幫助原始數據變得更適合用於建模和分析。
先來回憶上次的程式碼,這次也需要用到它們喔!(要特別注意程式碼第二行,需要補進去不然會出錯)
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
#上面這行這次要補進去喔,因為會需要用到to_categorical這個功能
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
(X_train,y_train),(X_test,y_test)=mnist.load_data() #一樣的載入mnist的資料集
那我們今天要做的第一步驟就是把上次的2D陣列轉換成數值的1D向量
X_train=X_train.reshape(60000,784).astype('float32')
#reshape()就是用來改變陣列的shape,但並不會改變它的數值。
把從28*28變成784(28*28=784)
X_test=X_test.reshape(10000,784).astype('float32')
#從unit8轉換成float32,雖然會佔據比較多的內存,但是希望可以保障數據的精準度還有計算效率
複習一下,6000張手寫圖片,28 * 28的矩陣(如下圖)
第二步驟
X_train /= 255
#把X_train/255,將像素值縮放到 0 到 1 之間,(因為原始數據的像素值範圍是 0 到 255)這樣做可以幫助我們提高模型的性能以及加速它的訓練,這個動作稱作稱為歸一化(有點像是數學中的標準化)
X_test /= 255
#上面的寫法就等於X_test=X_test/255
X_train[0]
#查看歸一化的第一筆資料
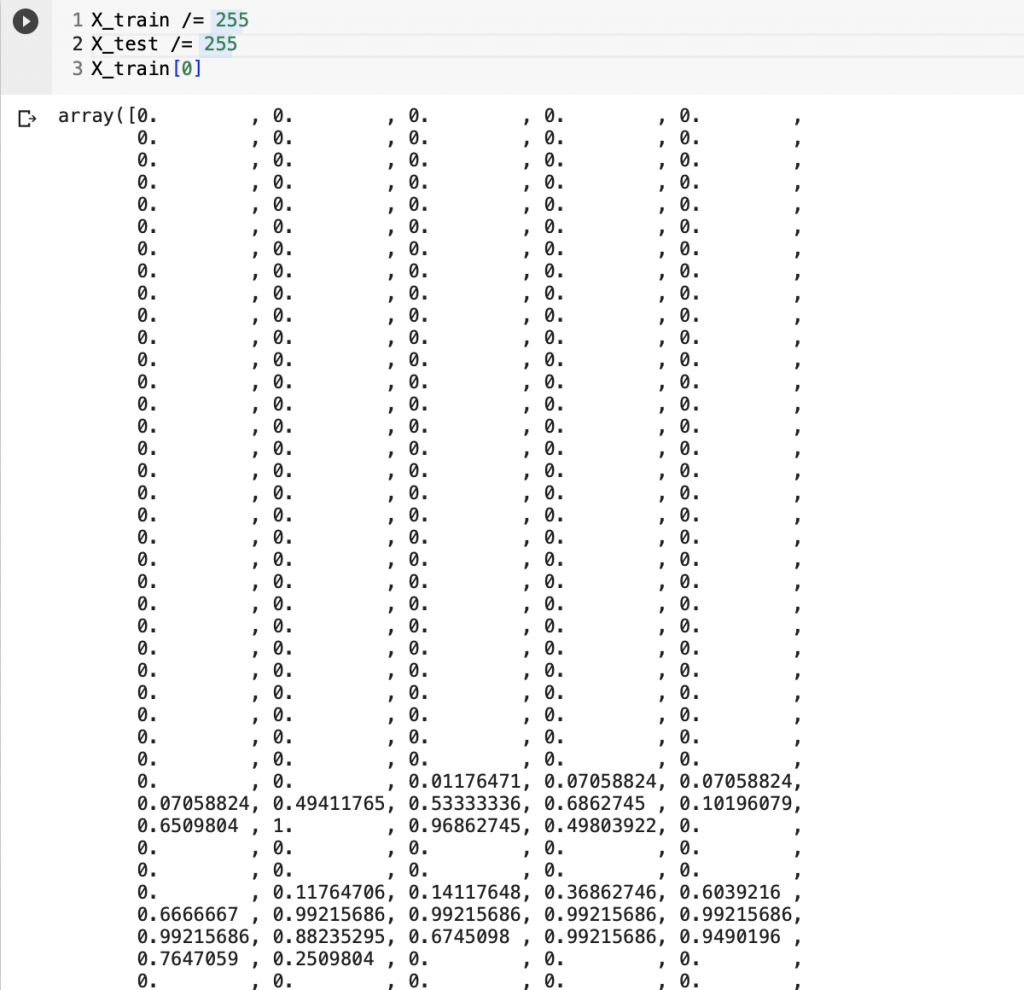
會發現所有的像素值都成功被我們轉換在1-0之間
y資料集的部分我們也需要做處理,因為他們現在的狀況是一個標籤,拿作天的例子來看,昨天的X_test[0]是圖片數字7,y_test[0]=7,我們要把它用one-hot的編碼來處理一下(忘記的人可以去看第一天複習一下喔),會變成這樣[0,0,0,0,0,0,0,1,0,0]索引數字0-9,索引數字7的位置是1,表示機率是100%,其他都是0(機率0%)
n_classes=10
#0-9的是數字機率
y_train= to_categorical(y_train,n_classes)
#to_categorical簡單來說就是把類別向量轉成只有0和1的表示,就會是one hot encoding的形式
y_test=to_categorical(y_test,n_classes)
y_test[0] #轉換完成後來看看索引數字7變成什麼樣子

這樣就可以方便我們把模型的輸出預測值做出對比,如果輸入數字7手寫圖片,那模型預測是數字7的機率值就會接近1,示範一遍test的資料集,大家快去試試看train的資料集會是什麼樣子吧!


 iThome鐵人賽
iThome鐵人賽